
DevOps and AI: Cutting-Edge Use Cases and Real-World Applications
DevOps practices are revolutionizing AI/ML workflows making it faster and safer to build, deploy, and maintain machine learning models in production. This convergence—often called MLOps (Machine Learning Operations)—applies DevOps principles like automation, continuous integration, and infrastructure-as-code to the ML lifecycle. The result is that data scientists and engineers can collaborate more efficiently, delivering smarter AI solutions with higher reliability. Conversely, AI techniques are also supercharging DevOps by automating monitoring, detecting anomalies, and optimizing resources in software delivery pipelines. The sections below outline the most compelling use cases at this intersection, with real-world examples, benefits, and technical insights.
DevOps Practices Accelerating MLOps (AI/ML Workflows)
Modern MLOps pipelines borrow heavily from DevOps culture and tooling to streamline model development, testing, deployment, and monitoring. Key practices include continuous integration/continuous delivery (CI/CD) adapted for ML, GitOps for configuration and reproducibility, automated model monitoring with feedback loops, and infrastructure automation for scaling experiments. These practices dramatically improve the speed and confidence with which ML-driven features can be delivered. The table below highlights major DevOps-for-AI use cases, their benefits, and real-world examples:

| DevOps Practice for ML | DevOps Practice for ML | Real-World Example & Outcome |
| CI/CD & Automation for ML | Rapid, repeatable model releases; automated testing catches issues early; quick rollback on failures | Uber Michelangelo platform gives engineers one-click deployment of models with built-in testing and rollback, enabling fast iteration across thousands of models |
| GitOps & Infrastructure as Code | Consistent environments across dev–staging–prod; reproducible experiments; auditable changes in config | Microsoft uses GitOps-driven ML pipeline (e.g. using DVC and CML) stores data, code, and model configs in Git. This ensures any team member can reproduce experiments and that model promotions to production follow controlled pull requests |
| Continuous Monitoring & Retraining | Early detection of model drift or performance drops; automated retraining or rollback; sustained model accuracy in production | Netflix’s Metaflow monitors model performance (accuracy, latency, etc.) and triggers retraining when metrics degrade beyond a threshold, ensuring recommendations stay high-quality over time |
| Experiment Tracking & Reproducibility | Organized record of experiments; easy comparison of model versions; team-wide sharing of results; no lost progress | Meta (Facebook) uses experiment tracking tools (e.g. Comet.ml) to log hyperparameters, code, and metrics for every run. This lets engineers compare models side-by-side, reproduce results, and make data-driven improvements faster |
| Feature Stores & DataOps | Single source of truth for features; consistent data for training vs. serving; reuse of features across models; faster development | Lyft’s Feature Store (built on the open-source Feast) centralizes key features for rideshare models. It ensures that the same features computed during training are available in production, preventing training-serving skew and reducing duplicate engineering |

Continuous Integration & Delivery (CI/CD) for Machine Learning
Just as CI/CD transformed software delivery, it’s doing the same for ML by automating the path from model code to production deployment. Continuous integration for ML involves not only merging code changes but also automatically testing models on fresh data and evaluating performance metrics (accuracy, AUC, etc.) before they are accepted. For instance, Uber’s Michelangelo platform includes robust automated tests that validate each new model version against predefined benchmarks and even perform A/B comparisons with the live model. Only models that meet quality gates are allowed to deploy, preventing regressions in accuracy or latency.
On the delivery side, continuous deployment of ML models can be tricky – not just deploying an artifact, but also handling model packaging (serialization, containerization), dependency management (e.g. specific versions of libraries), and environment setup (like GPUs or specialized hardware). DevOps tooling addresses this by using containerization and infrastructure-as-code to standardize environments. Uber’s Michelangelo automates model packaging into Docker containers and uses a single-click deploy pipeline, so data scientists can push a button to release a model to production with the confidence that the serving environment mirrors training. Crucially, Michelangelo also implements safe deployment practices: models are rolled out gradually and include a quick rollback mechanism. If a new model causes anomalies in production (say, a spike in error rate or prediction latency), the platform can immediately revert to the previous model version with one click. This kind of automated rollback, combined with monitoring (discussed below), gives teams a safety net when continuously delivering ML updates.
Real-world impact: Embracing CI/CD for ML yields faster iteration and more reliable outcomes. Uber credits Michelangelo’s CI/CD approach for enabling rapid experimentation at scale – they can retrain and deploy models for pricing, ETA prediction, or fraud detection across dozens of teams, all using a unified pipeline. The outcome is that improvements move from research to production in days instead of months, conferring a competitive edge. Even smaller organizations can implement CI/CD for ML using tools like Jenkins or GitHub Actions combined with ML-specific extensions (for example, Continuous Machine Learning (CML) by Iterative.ai can report model metrics in pull requests). This ensures that every model update is automatically tested and versioned, and deployments become routine. In summary, CI/CD brings to ML the discipline of frequent, automated, and safe releases, allowing AI-driven features to evolve rapidly without sacrificing quality.
GitOps and Infrastructure Automation for AI Workloads
Reproducibility is a major challenge in ML (think “it worked on my machine” syndrome, but with data and models). GitOps, which treats Git as the single source of truth for infrastructure and deployments, is a game-changer for ML systems. By expressing not only code but also data pipeline configs, model parameters, and deployment manifests as code in a Git repository, teams create an auditable, revertible history of the entire ML lifecycle. This approach enhances governance and collaboration: any change to an ML workflow (be it a data preprocessing step or a model hyperparameter) is done via version-controlled commits, so it’s clear who changed what and when. In regulated industries, this traceability is gold — you can answer exactly which model version and data went into a particular decision.
A GitOps workflow typically involves automated synchronization between the Git repo and the running environment. For ML, one pattern is to use branch-based promotions: for example, a team might use a staging branch for model testing and a production branch for live models. Merging a model’s code and config into production could trigger an automated deployment of that model to production infrastructure (using tools like Argo CD or Flux). In one case study, an ML team maintained separate Git branches for experimental models, and when a model was ready they would merge into main which kicked off GitHub Actions to register the model and deploy it through staging to prod. This push-to-deploy automation ensures consistency: the model that was evaluated in staging is exactly what goes to production, because everything (from model binary to infrastructure definition) comes from the merged Git state.
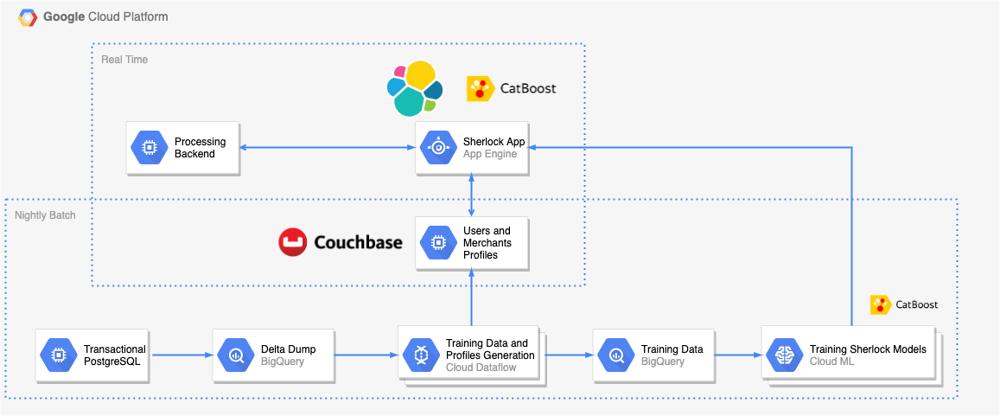
Another aspect is Infrastructure as Code (IaC) for AI. Using IaC tools (Terraform, CloudFormation, etc.) to provision cloud resources for ML jobs means environments can be created and destroyed on demand. This is especially powerful for ephemeral heavy workloads like model training. For example, a team can codify a GPU cluster setup and spin it up only when a training pipeline runs, then tear it down to save cost – all triggered by CI and governed in code. Cloud providers also offer managed services (like AWS SageMaker or GCP Vertex AI) which integrate with IaC. A fintech startup might use Terraform scripts to set up a pipeline where new training data in a bucket triggers a SageMaker training job, and upon completion, the resulting model artifact is automatically deployed behind an endpoint. Revolut’s “Sherlock” fraud detection system is a great example of leveraging cloud automation: they orchestrated training and deployment with Google Cloud Composer (Airflow) and deployed the model as a serverless service on Google App Engine, so the entire pipeline from data extraction to real-time prediction was managed without manual intervention. This allowed them to train nightly on fresh transactions and serve predictions in production with ~50ms latency per request, all in a fully automated, scalable manner.
Overall, GitOps and IaC bring rigor and efficiency to ML ops. Teams get reproducible experiments (you can rerun any experiment by checking out an old Git commit and re-running the pipeline), easier troubleshooting (config mismatches are eliminated, since dev/prod use the same code), and faster onboarding (new team members can spin up the whole ML stack from code). Companies adopting this approach have reported smoother collaboration between data scientists and engineers, since everyone works off the same Git repo rather than ad-hoc scripts. As one source notes, storing ML experiment configurations and data versioning info in Git makes it “easier to recreate experiments and understand how changes affect results”. In essence, GitOps for ML treats ML models and data pipelines as first-class code, yielding the same benefits of agility and reliability that DevOps brought to traditional software.

Revolut’s Sherlock ML pipeline uses fully managed cloud infrastructure. Training data is prepared via Apache Beam on Dataflow, stored in BigQuery, and fed to CatBoost model training (Google Cloud ML). The trained model is deployed as a Flask app on App Engine, where it serves real-time fraud predictions (with cached profiles from Couchbase) – all orchestrated automatically in a CI/CD workflow.
Monitoring, Model Performance Management, and Rollbacks
Once a model is deployed, the DevOps mindset shifts to continuous monitoring and rapid feedback – treating the model in production as a living system to watch, rather than a one-and-done release. This is critical because ML models can degrade over time (data drift, concept drift, etc.). Leading AI-driven companies implement extensive monitoring similar to application APM, but focused on model metrics and data quality. For example, Netflix instrumented its ML workflows via their Metaflow framework to track key metrics like prediction accuracy, user engagement, input data distributions, and latency in real-time. Alerts are set up (using tools like Prometheus and custom dashboards) to flag if a model’s performance dips below a threshold or if incoming data starts to differ from training data (a sign the model might become stale). Netflix even built an internal tool called Runway to automatically detect “stale” models (models that haven’t been retrained in a while or are underperforming) and notify teams.
Automated retraining and rollback are two DevOps-style responses to issues detected by monitoring. In Netflix’s case, they have automation that triggers a model retraining job when concept drift is detected, so the model can update itself to new patterns in user behavior without engineers manually intervening. In parallel, some organizations choose an alternative strategy: if a model starts misbehaving, they roll back to a previous known-good model version (since all models are version-controlled and stored). Uber’s Michelangelo, as noted, has a one-click rollback to the last model if the new one has problems. Which approach to use might depend on the use case – high-frequency retraining is great for things like recommendation systems that have constantly evolving data, whereas rollback might be the safer bet for, say, an ML model in a medical device if an update goes wrong.
Case in point: E-commerce company Holiday Extras uses monitoring to ensure their price optimization models don’t drift. They log every prediction to a BigQuery warehouse so that data scientists can periodically analyze how the predictions compare to actual outcomes, using statistical tests to catch drift. When anomalies are detected (e.g. the model’s error rate increasing), they retrain the model on recent data and redeploy – effectively a manual but systematic feedback loop. On the other hand, Netflix’s MLOps is more automated – their system continuously evaluates live model performance and has A/B testing infrastructure to roll out changes to a subset of users to gauge impact safely. This DevOps-like experimentation culture (test in production, measure, and then go wide) allows them to innovate on algorithms (like new recommendation models) with minimal risk to user experience.
The benefits of strong monitoring and automated responses in ML are huge: higher uptime for AI services, better accuracy over time, and trust in the AI from stakeholders. Instead of models being “fire and forget,” they become continuously improving services. Teams can confidently deploy models knowing there’s a safety net if things go wrong. Moreover, comprehensive logging and monitoring support governance and debugging – if a prediction was wrong, you can trace exactly which model version and data were used (many teams log a “prediction trace” with model ID, input features, and prediction result for each request). This is analogous to application logs and greatly helps in root cause analysis of issues, a concept we’ll revisit in the AIOps section.
Experiment Tracking and Reproducibility
In fast-paced ML teams, dozens of experiments may be run weekly – trying different model architectures, features, hyperparameters, or data preprocessing techniques. Experiment tracking tools, inspired by the DevOps emphasis on traceability, have become essential to manage this chaos. At its core, experiment tracking means logging every experiment’s details and outcomes to a central repository. Key details include: code version (Git commit hash), dataset used, parameters, training metrics, and the final model artifact. This practice ensures that any result can be later reproduced and verified – critical for debugging and for regulatory compliance in sensitive applications.
A great example is Meta (Facebook), which deals with incredibly complex ML models (e.g. for feed ranking or ads). Meta uses internal platforms (and sometimes external tools like Comet.ml or Weights & Biases) to record each experiment. Suppose an engineer tries a tweak that improved the accuracy by 1% – with proper tracking, they can compare that run against others to make sure it wasn’t a fluke, and teammates can see those results too. According to one case study, tracking solutions like Comet.ml provide visual dashboards to compare different runs side by side and even integration into CI pipelines for automated logging. This kind of transparency is invaluable for collaboration: a new team member can review past experiments to understand what’s been tried. Meta’s teams reportedly leverage these tools to iterate rapidly – they can quickly identify which hyperparameters matter most by analyzing logged experiments, and they avoid repeating failed approaches because everything is documented.
Beyond tools, there’s a cultural aspect: a DevOps mindset applied to ML means treating experiments like code deployments. Every experiment is traceable (via an ID or Git branch), and ideally, any model in production is linked back to an experiment record. Companies like Airbnb have even added experiment tracking into their workflow: they use notebooks and pipelines that automatically log results to a shared system, so even ad-hoc analyses get tracked for posterity. The payoff is reproducibility – if a model is doing something unexpected, you can recreate the exact conditions under which it was trained. It also facilitates knowledge sharing and onboarding, much like a well-documented codebase does.ter models.
In summary, experiment tracking and reproducibility practices (like versioning datasets and models, using platforms such as MLflow, Neptune, Comet, or internal solutions) bring order to ML development. They enable data-driven decisions (you can literally plot experiment results over time to see if you’re converging to better performance), and they instill confidence that models are not magic but the result of consistent, repeatable processes. As one ML engineer put it, effective experiment tracking lets teams “ensure reproducibility of workflows and collaborate more effectively,” ultimately leading to better models.
Feature Stores and DataOps for ML
Feeding the ML beast with consistent, high-quality data is just as important as model code. This is where DataOps (data engineering inspired by DevOps) and feature stores come in. A feature store is a centralized database that stores curated features (input variables) for ML models, along with their historical values. The concept addresses a common gap: often, data scientists compute features in a notebook for training, but in production those same calculations need to be redone in a live system – if done inconsistently, the model sees different data than it was trained on. Feature stores solve this by acting as the single source of truth for feature calculations: the ML pipeline writes features to the store during training, and the serving system reads from the store to get the latest feature values for predictions.
Lyft’s feature store journey is illustrative. As Lyft’s ML usage grew (for ETAs, pricing, fraud, etc.), they found duplication and inconsistency in how features (like “ride distance” or “time of day”) were computed across teams. They implemented an internal feature store (using an open-source foundation called Feast) to centralize these computations. Lyft’s feature store allowed teams to reuse features easily, so a feature engineered by the fraud team could be applied to a new model by the pricing team without re-writing code. This not only saved development time but also improved consistency – a given feature had one definition, ensuring the model in training and the model in production were looking at the same inputs. Similarly, Uber built a feature store named Palette as part of Michelangelo, and it uses it with a combination of Cassandra and Hive to serve features for both batch and real-time models.
On the DataOps side, DevOps culture has influenced how data pipelines for ML are built and managed. Continuous integration for data means every change in data processing code is tested (with checks for data quality). Airbnb, for example, treats data pipeline changes with the same regularity as application code: they use Apache Airflow with automated validation tests on datasets and schema versioning. By doing so, they catch upstream data issues before they wreak havoc on models. Airbnb even developed a unified platform called Metis for data management, which among other things tracks data lineage and quality across their organization. This investment in DataOps directly boosts their ML effectiveness: models are only as good as the data they train on, so having fresh, reliable data pipelines means better model outcomes and fewer emergency fixes.
To sum up, DevOps-style management of data and features through DataOps practices and feature stores yields a “wow” effect by drastically reducing one of the biggest headaches in ML (data inconsistency). It ensures that as data flows from raw sources to refined features to model predictions, everything is versioned, tested, and consistent. The strong value proposition here is faster development (no need to reinvent feature calculations), higher accuracy (train/serve consistency), and team scalability (data engineers can focus on building robust pipelines, while data scientists trust the data and focus on modeling). In production use, this translates to models that perform better and more predictably – which ultimately means better business outcomes from AI initiatives.
AIOps: AI-Driven Enhancements to DevOps
The influence goes both ways: just as DevOps improves AI workflows, AI is being applied to improve DevOps processes. AI for IT Operations (AIOps) is an emerging field where machine learning models and intelligent automation are used to make software operations and delivery smarter and more autonomous. These applications are exciting for any tech team looking to tame complex systems or gain an edge in reliability. Below are some of the most impactful AI-driven use cases in DevOps, from smarter monitoring to self-healing systems, along with examples of how organizations benefit.

Monitoring and Anomaly Detection
Traditionally, operations teams set static thresholds on metrics and rely on alerts to catch issues (e.g. CPU > 90% triggers an alarm). AI is upending this with anomaly detection algorithms that learn the normal patterns of system behavior and can spot subtle deviations in real-time. For instance, instead of alerting only when CPU > 90%, an AI model can analyze multi-metric patterns (CPU, memory, request latency, error rates) and detect when the combination is “unusual” compared to historical baselines. This means incidents can be caught earlier and with fewer false alarms. Companies are embedding such models into their monitoring stacks: AIOps platforms or tools like Datadog, Dynatrace, and Splunk have built-in ML that continuously analyzes metrics and logs. At xMatters (a service reliability platform), they apply AI to “thousands of metrics across IT systems in real-time” and automatically trigger alerts only for abnormal behavior, suppressing the noise of normal fluctuations. This intelligent alerting greatly reduces alert fatigue for on-call engineers, who no longer have to sift through hundreds of trivial alerts.
A related use of anomaly detection is in CI/CD pipelines and testing. Here, AI can watch build or test logs and identify patterns that indicate a failure is likely, even if the tests haven’t outright failed yet. For example, an ML model could learn that a certain sequence of warnings in logs often precedes a deployment failure. Integrating such a model into a Jenkins or GitHub Actions pipeline means the pipeline can automatically pause or rollback when an anomaly is spotted in the build output. A recent demonstration showed a GitHub Actions workflow with an ML step that parses build logs and flags anomalies: if the model predicts something off, the deployment step is skipped. The benefits were clear – fewer failed deployments reaching production, and developers saved from manually checking lengthy log files. In practice, this kind of predictive QA can also optimize testing itself: some teams use AI to predict which test cases are likely to fail given the code changes, and run those first (or run a reduced set of tests), speeding up feedback. Microsoft has experimented with such techniques to prioritize tests in their massive codebases.
In summary, AI-driven anomaly detection brings a “guardian angel” into DevOps pipelines and monitoring. It tirelessly learns what “normal” looks like and catches the weird stuff instantly. This not only prevents many incidents but also frees human operators from watching dashboards 24/7. As one writer put it, AI in CI/CD can “reduce failed deployments” and “save developers from manually reviewing build logs” by automatically identifying problems. It’s like having an expert assistant who never sleeps, making your delivery pipeline and production environment more resilient.

Root Cause and Incident Response
When something does go wrong in a complex system, figuring out why can be like finding a needle in a haystack. AI is proving incredibly useful for root cause analysis (RCA) by correlating data from many sources and pinpointing the most likely cause of an incident. Imagine a microservices architecture where a user-facing error could originate from dozens of interconnected services – an AIOps system can analyze logs, traces, and metrics across all services to find the chain of events that led to the error. These systems often use graph algorithms and machine learning to correlate timings and anomalies. The outcome is a hypothesis like, “90% of the time when Service A slows down and errors spike, Service B had a memory spike 5 minutes earlier,” giving operators a lead on where to focus. According to an AIOps case study, modern incident management tools “streamline root cause analysis using advanced ML algorithms and event correlation”, reducing the time it takes to diagnose issues dramatically.
Leading companies have started building this into their ops process. For example, PayPal developed an internal AI tool that ingests all their logs and metrics and uses a form of unsupervised learning to cluster related anomalies, effectively telling engineers “these 5 alerts are all part of the same incident.” This saves them from being overwhelmed by redundant alerts and guides them to the real cause. Similarly, IBM’s Watson AIOps and other vendor solutions offer an “incident insights” feature where a chatbot or dashboard will highlight the likely root cause (e.g., a specific Kubernetes pod or a recent deployment) by analyzing the incident data against historical incidents. The real power here is reducing MTTR (Mean Time To Resolution): AI might crunch in seconds what would take humans hours. One source notes that by leveraging AI for real-time root cause analysis, teams can swiftly identify underlying causes and cut down both MTTD (Mean Time to Detect) and MTTR. Faster RCA means quicker fixes and less downtime.
Beyond analysis, AI is also enabling automated incident response or remediation – essentially self-healing systems. For instance, an AIOps system might detect a memory leak and automatically restart the affected service or clear a cache, based on learned behavior or runbooks. Some organizations implement automated rollback if a deployment is detected as the root cause: Facebook is known to automatically halt and roll back code pushes if their monitoring detects user impact, using algorithms to determine that the latest change is likely to blame. This kind of closed-loop remediation can be risky, but when done carefully (only for certain types of issues that are well-understood), it can dramatically reduce outage time. We’re inching into the realm of NoOps – where the system manages itself to some degree. While human oversight is still crucial, AI assistance means ops teams can handle larger systems with more confidence. As xMatters highlights, AIOps not only finds root causes but can also “trigger automated responses or alert IT teams to act immediately when abnormal behavior is detected” – effectively serving as an intelligent first responder that stabilizes the situation until humans take over.
Predictive Scaling and Resource Management
Another compelling intersection is using AI/ML to optimize infrastructure and resource usage – essentially applying predictive analytics to questions like “when will we need more servers?” or “how can we reduce cloud costs without hurting performance?”. This is often dubbed predictive auto-scaling or adaptive capacity planning. Traditional auto-scaling uses reactive rules (add instances when CPU > 70% for 5 minutes, etc.), but AI can forecast demand spikes in advance by analyzing patterns (e.g., daily cycles, seasonal trends, marketing events, etc.). For example, an e-commerce site might train a model on its traffic data to predict each morning how much load the evening will bring, and proactively scale up capacity before the rush, avoiding any performance hiccup. Amazon Web Services itself uses predictive scaling for some of its services, and companies like Netflix (with their demand forecasting for streaming) pioneered this approach to ensure they had enough servers ready for prime time viewing.
From a cost perspective, this also ties into FinOps (Cloud Financial Ops). Over-provisioning is costly, but under-provisioning hurts reliability. AI helps find the sweet spot by continuously optimizing resource allocation. Tools like IBM Turbonomic (mentioned by IBM in AIOps context) analyze usage patterns and automatically adjust resources – for instance, resizing containers or VMs based on predicted workload. This can lead to significant savings by shutting off idle resources and right-sizing overpowered instances, all while maintaining performance. In one use case, Carhartt (a retail company) used an AI-driven optimization tool and reportedly achieved record holiday sales without performance issues, while keeping cloud costs in check.
AIOps-driven resource management isn’t just about VMs and containers – it can also optimize CI/CD pipelines (e.g., allocating more CI runners at predicted peak commit times to keep build times short) and data pipelines (throttling or reallocating resources to critical jobs). Essentially, any part of the DevOps toolchain that consumes compute could benefit. As one blog noted, AIOps solutions can predict future resource needs and prevent over- or under-utilization, ensuring efficient use of resources while keeping performance at its peak. This is done by analyzing historical data and spotting trends that humans might miss, then applying actions like scaling or rebalancing workloads. The end result is a more elastic and cost-effective infrastructure, run by policies that learn and improve over time.
For organizations, the “wow” factor here is twofold: savings and resilience. AI can cut cloud bills by finding waste (one company discovered via an ML tool that 30% of their servers were never used on weekends, leading them to automate shutting those down on Fridays). And it can prevent incidents by making sure resources are there when needed – a kind of AI-powered safety margin that expands and contracts dynamically. Tech leaders often cite these benefits: reduced costs, less manual tuning, and the ability for a small DevOps team to manage infrastructure at massive scale by relying on smart automation.
Bottom line: The intersection of DevOps and AI is producing innovative solutions that excite technical teams. DevOps practices (CI/CD, GitOps, automation) are turbocharging AI/ML projects – enabling faster development cycles for models, more reliable deployments, and scalable infrastructure for data and compute-heavy tasks. This means even startups and midsize businesses can iterate on AI features as quickly and safely as software features, which is a huge competitive advantage. On the flip side, AI is making DevOps smarter – from pipelines that heal themselves or optimize their own performance, to operations that preempt issues before users notice.
For a savvy engineering audience, these trends offer a glimpse of a future where ML models go to production with push-button ease and keep improving autonomously, and where DevOps pipelines manage themselves with intelligent guardrails. The case studies above – from Uber’s and Netflix’s sophisticated MLOps platforms to real-world examples like Revolut’s fraud system and intelligent CI pipelines – demonstrate that this is not just theory but actively shaping industry best practices. Embracing these ideas can lead to more innovative, resilient systems with clear business value, whether it’s delivering new AI-driven features faster or achieving near-zero downtime through predictive operations. The marriage of DevOps and AI is truly a win-win, and we’re just seeing the beginning of what’s possible when these disciplines reinforce each other.